Me encantan los Open Spaces. Mi primera experiéncia fue en Buenos Aires en marzo de 2009, y supuso una revolución para mi en la forma de encarar la organización de eventos. El segundo fue el del año pasado en Barcelona, en el que, a parte, participé en la organización. Y este fin de semana se realizó el Agile Open Spain 2011 en Pamplona, al que no podia faltar. Como siempre me encontré allí a un montón de amigos, aunque la novedad de este año fue poder ir acompañado de casi la totalidad de la gente de la oficina de Plain Concepts en Bilbao.
Una de las razones por las que me encantan los Open Spaces es porque creo que ejemplifican a la perfección el espiritu del agilismo. Es un evento hecho por la comunidad para la comunidad. Por supuesto que necesita un comité organizador ( y que lo hicieron a la perfección ) para todo el tema logístico, pero la "chicha" del evento, las 36 charlas que hubo, fueron un trabajo de los miembros de la comunidad para los miembros de la comunidad. Se formaron 36 equipos enfocados en dar el máximo valor posible a las charlas.

Yo propuse una charla sobre calidad del código que fue bien recibida y que creo que estubo bastante bien, aunque no se tocaron todos los temas que me hubieran gustado. La discusión se centró sobretodo en la cobertura de tests y en los comentarios en el código. También se habló de los equipos de QA.
Por otra parte asistí a charlas tan variopintas como Stubs, Mocks y Spies, taller práctico de histórias de usuario, talento, estimaciones, deduda técnica y romper la rutina.
Por encima de las charlas en sí ( que podéis ver en detalle en los diferentes resúmenes hechos por los participantes ) yo me quedo con las personas que asistieron al evento. Se reunieron 150 personas preocupadas por su profesión, con ganas de mejorar su entorno, con ganas de hacer cosas para ellos y para los demás y comprometidos con la excelencia.
Espero ya con ganas el Agile Open Spain del año que viene, en el que espero veros a muchos de vosotros.
Un saludo!
Una de las razones por las que me encantan los Open Spaces es porque creo que ejemplifican a la perfección el espiritu del agilismo. Es un evento hecho por la comunidad para la comunidad. Por supuesto que necesita un comité organizador ( y que lo hicieron a la perfección ) para todo el tema logístico, pero la "chicha" del evento, las 36 charlas que hubo, fueron un trabajo de los miembros de la comunidad para los miembros de la comunidad. Se formaron 36 equipos enfocados en dar el máximo valor posible a las charlas.
Yo propuse una charla sobre calidad del código que fue bien recibida y que creo que estubo bastante bien, aunque no se tocaron todos los temas que me hubieran gustado. La discusión se centró sobretodo en la cobertura de tests y en los comentarios en el código. También se habló de los equipos de QA.
Por otra parte asistí a charlas tan variopintas como Stubs, Mocks y Spies, taller práctico de histórias de usuario, talento, estimaciones, deduda técnica y romper la rutina.
Por encima de las charlas en sí ( que podéis ver en detalle en los diferentes resúmenes hechos por los participantes ) yo me quedo con las personas que asistieron al evento. Se reunieron 150 personas preocupadas por su profesión, con ganas de mejorar su entorno, con ganas de hacer cosas para ellos y para los demás y comprometidos con la excelencia.
Espero ya con ganas el Agile Open Spain del año que viene, en el que espero veros a muchos de vosotros.
Un saludo!








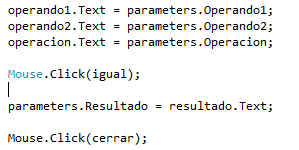


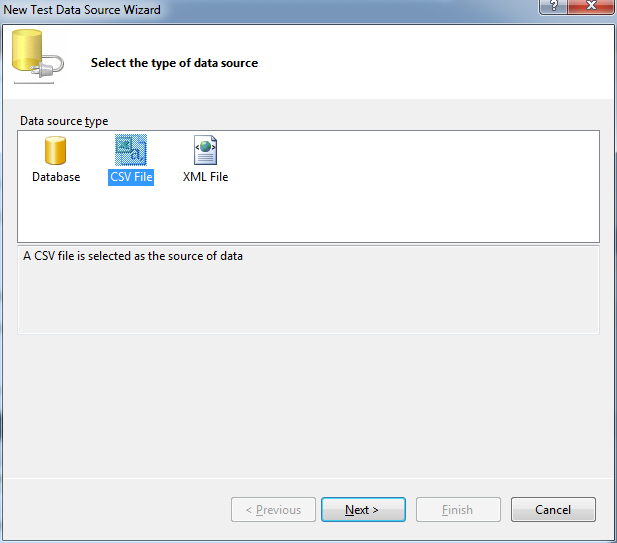
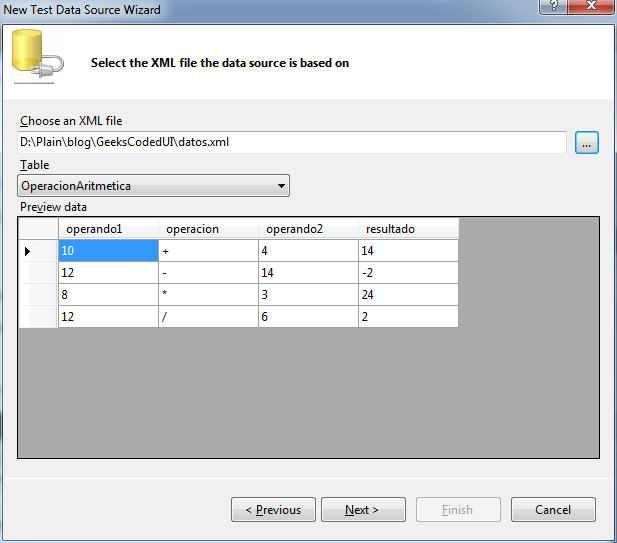
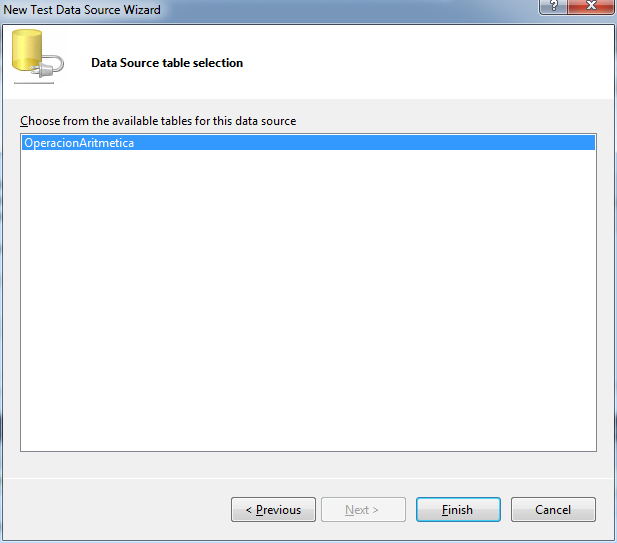



{kind=link}
{kind=link}
{kind=link}